Introduction
La traduction fait partie intégrante de notre monde, mais la langue des signes fait exception. En France, la loi pour l’égalité des droits et des chances, la participation et la citoyenneté des personnes handicapées parue en 2005 reconnaît la Langue des Signes Française (LSF) comme une langue à part entière, et comme une langue de la République au même titre que le français. De cette loi devrait découler une accessibilité totale en LSF pour les personnes sourdes (accueil dans les lieux publics, messages audio diffusés, information écrite). Renforcé par l’adoption en 2008 de la Convention sur les Droits des Personnes Handicapées par les Nations Unies, le besoin pour du contenu accessible et donc traduit en LSF est croissant. Cependant, il n’y a en France encore que très peu de traducteurs professionnels, et ces derniers ne sont en rien équipés comme le sont leurs collègues des langues vocales : aucun outil actuel de traduction assistée par ordinateur n’existe pour assister la traduction des langues signées. L’article se propose d’explorer les possibilités pour outiller le métier de traducteur en LS.
La section 1 décrit les fondamentaux des langues des signes, et permet de poser le contexte dans lequel se situe notre recherche. La section 2 fait l’état de travaux existants en lien avec notre thématique. Pour répondre à notre problématique, il nous faut connaître le métier et ses tâches constitutives, ce dont traite la section 3. La section 4 est quant à elle dédiée à la présentation d’un outil que nous proposons en réponse à l’un des problèmes soulevés lors de nos expériences. Enfin, la section 5 propose quelques perspectives quant à la poursuite de la recherche.
1. Contexte LSF
Les langues des signes (LS) sont des langues naturelles et orales qui utilisent les modalités visuo-gestuelle pour transmettre du sens, au travers d’articulateurs manuels, de mouvements du corps, du regard et des expressions du visage. Là où les langues vocales sont généralement contraintes par la linéarité (nous ne pouvons physiologiquement produire qu’un seul son à la fois), les LS expriment plusieurs informations simultanément. Elles font un grand usage de références spatiales persistantes dans leur organisation, qui peuvent être réutilisées dans la suite du discours. L’organisation du discours en LS commence par une description préliminaire de la scène : on situe d’abord l’évènement dans le temps, puis on introduit les lieux, les personnages. L’action en elle-même n’est traitée que dans un second temps. Une fois qu’un lieu, un objet ou une personne a été introduit et défini dans l’espace, le locuteur pourra le/la citer de nouveau plus tard dans le discours par le biais de sa référence spatiale : l’interlocuteur sait maintenant que cet espace correspond à tel ou tel personnage, sans avoir besoin de le renommer à chaque occurrence.
Les LS sont des langues iconiques, c’est-à-dire que les signes sont le plus souvent inspirés de la réalité (ce que la linguistique appelle l’iconicité, CUXAC, 1993). Par extension, elles sont parfois contraintes par la réalité, notamment lorsqu’il est question de géographie, ou de topologie. En effet, le contenu en LS se doit d’être grandement visuel, et précis lorsqu’il se réfère à des relations existantes dans la réalité. Par exemple, lorsque l’on signe à propos de deux villes, et de la relation géographique qui les unit, le signeur doit coller au mieux à la réalité. Cela signifie qu’il doit convenablement situer les deux villes dans l’espace l’une par rapport à l’autre, en termes de distance et d’orientation.
Bien qu’il existe plusieurs systèmes pour décrire les LS sous forme graphique (SignWriting, HamNoSys par exemple), ils ne sont pas suffisamment utilisés par la communauté sourde elle-même pour pouvoir être considéré comme des formes écrites des LS. Les LS n’ont donc pas de forme écrite standard, formelle et éditable comme celles dont on dispose pour l’anglais ou le français. La façon la plus courante pour garder une trace dans le temps d’un discours en LS est de passer par l’enregistrement vidéo. Ces vidéos ne sont cependant pas facilement requêtables, ni éditables ou même partageables comparées à du simple texte ou à de l’information écrite. La section suivante présente un état de l’art actuel concernant la traduction en LS ainsi que la traduction assistée par ordinateur.
2. Travaux reliés
Comme nous allons le voir, aucun travail de recherche ne traite directement de notre problématique. Les paragraphes suivants s’intéressent à des travaux au moins partiellement connexes : la traduction des LS sans outils informatiques, la traduction des LS outillée mais sans implication humaine, et enfin la traduction assistée par ordinateur sans lien avec les LS.
2.1 La traduction des LS sans informatique
Il est question ici de traduction des LS, et non d’interprétation. Bien que les deux processus aient pour but de faire passer un message d’une langue vers une autre, il s’agit de deux tâches différentes. Pour poser une distinction claire entre les deux, retenons que le traducteur a l’opportunité de retravailler plusieurs fois sa production, puisqu’il travaille en différé. L’interprète lui, opérant en direct, ne peut proposer qu’une seule version de sa production, sans la possibilité de l’éditer de nouveau par la suite. Il n’est pas rare cependant, que des interprètes en langue des signes doivent supporter des tâches de traduction ponctuelles du fait du manque de traducteurs professionnels.
Comme pour la traduction langue vocale vers langue vocale, l’objectif de la traduction en LSF est de transmettre le sens d’un message du français écrit vers la LSF ou inversement. Pour ce faire, le changement de langue implique ici également un changement de modalité, et par extension, de schéma de pensée. Traduire du français vers la langue des signes française suppose un passage par la pensée visuelle, c’est-à-dire qu’il s’agit de mettre le sens en image. Cette étape supplémentaire, dite de déverbalisation, permet d’affranchir la traduction de l’influence des constructions de l’écrit sans tomber dans le transcodage. L’exercice de reformulation, couplé à l’usage de schémas, permet au traducteur d’extraire dans un premier temps le sens du message qu’il doit faire passer, et de le reconstruire dans un second temps sous une forme propice (GUITTENY, 2007. SELESKOVITCH & LEDERER, 2016). On retrouve d’ailleurs des enseignements dédiés à ces méthodes et pratiques au sein des différentes formations d’interprètes et traducteurs LSF. Si les références académiques traitant du sujet demeurent peu nombreuses, il existe cependant plusieurs travaux de terrain qui illustrent la réalité du métier et proposent des réflexions quant à ses pratiques. Il s’agit pour la plupart de mémoires de master, qui traitent du cadre pour le métier de traducteur LSF (PELATH, 2007), de la schématisation ou encore de la pensée visuelle et son lien avec les LS.
Du fait de la nature visuelle et iconique de la langue, la traduction en LS nécessite également une connaissance encyclopédique poussée, et donc un accès à des ressources variées. La sous-section suivante s’intéresse à l’existence d’outils dédiés aux LS et à leur traduction.
2.2 Traduction informatique des LS mais sans humain
De récentes études s’intéressent à la capture, à la reconnaissance ou à la génération automatique de signes. BUKHARI et al. (2016) ont notamment proposé un système de traduction du signe au texte sous forme d’application Android, basée sur l’usage d’un gant sensoriel. Les études de traduction texte vers LS sont généralement liées à la technologie d’avatar. C’est le cas de l’étude d’HALAWANI (2008), qui propose une application mobile pour la traduction de la langue des signes arabe. Elle combine un input sous forme de texte, dont le ou les signes correspondants aux mots identifiés sont ensuite animés par un avatar. L’avatar est basé sur une base de données de signes enregistrés via capture de mouvements.
Les ressources en LS étant rares, BARBERIS et al. (2011) et BERTOLDI et al. (2010) ont travaillé sur la langue des signes italienne. La première étude porte sur un système de machine translation, du texte vers un avatar signant. Ils font mention de traducteurs statistiques tels que MOSES, qu’ils ont entrainés pour la LS. La deuxième étude traite de la création d’un corpus parallèle italien/langue des signes italienne, dans le cadre du projet ATLAS. Ce corpus est destiné à l’entrainement d’un interprète virtuel sous la forme d’un signeur animé.
La traduction automatique des LS pourrait être à terme un élément à considérer, mais en l’état actuel des choses, elle n’apporte pas suffisamment d’avantages aux traducteurs pour être considérée comme utile en tant qu’outil de traduction. Les systèmes de traduction automatique pourraient être utilisés en TAO, mais nous souhaitons nous concentrer sur l’intégralité d’un environnement de travail intégré plutôt que juste sur un output. Notre objectif est d’équiper les professionnels de la traduction en LS avec des outils qui correspondent tant à leurs tâches qu’à leurs besoins. Nous n’avons actuellement pas encore trouvé de mention de logiciels de TAO à destination des LS où le traducteur humain serait impliqué, ni où l’opérateur humain demeure en charge de sa traduction. Il existe en revanche de nombreux outils logiciels destiné à assister la traduction texte à texte, dont nous détaillons les points clés dans la sous-section suivante.
2.3 Outils pour la TAO mais sans langue des signes
En étudiant les logiciels de TAO pour les langues écrites et vocales, nous avons pu déterminer que leur fonctionnement et leur efficacité reposent sur trois points clés, à savoir :
-
Une forme écrite éditable : tout est sous forme écrite, aussi bien le texte source que le texte cible (la traduction), mais également l’aide fournie par les outils annexes du logiciel (concordancier, glossaires, terminologie...).
-
La mémoire de traduction : elle stocke les alignements (c'est-à-dire chaque paire de segment source jumelé avec sa traduction) et permet de les réutiliser ultérieurement. Si le programme rencontre un segment déjà traduit par le passé, alors la mémoire de traduction suggère automatiquement la traduction précédente comme traduction possible. Le traducteur est libre d'accepter, de refuser ou d'accepter avec modifications. La mémoire de traduction est également un outil collaboratif, ce qui signifie qu'il peut être partagé entre collègues, au sein d’un même service, et même être fourni directement par les clients. D'une manière générale, c'est un moyen d'améliorer la cohérence entre les traductions, soit dans le temps, soit entre les personnes travaillant sur un même projet. Les alignements sont automatiquement produits et stockés tout au long du processus de traduction. Il n’existe actuellement aucune version pour les langues signées. C’est l’outil principal des logiciels de TAO pour le texte à texte, qui offre un gain de temps et de confort considérable pour les traducteurs.
-
Ce que nous appelons “le principe de linéarité”. Le logiciel segmente automatiquement le texte à traduire en plus petites unités. Chacune de ces unités est associée à une unité vide, que le traducteur traduit dans le même ordre pour obtenir la traduction finale. Autrement dit, la concaténation des segments traduits équivaut à la traduction des segments sources concaténés. Cet ordre ne peut pas être modifié dans le logiciel, qui ne semble autoriser la fusion partielle que de deux segments consécutifs.
De manière générale, l’assistance proposée par ces logiciels repose sur l’automatisation de tâches systématiques et répétitives. Le traducteur, s’il conserve sa place d’expert, n’a parfois pour tâche restante que de valider ou d’invalider les suggestions de la machine. Son expérience de traduction est très encadrée et guidée, et ne fait que peu appel à des ressources extérieures à celles qu’intègre le logiciel, qui sont conséquentes : glossaires, mémoires de traduction partageables, outils de terminologie, traduction automatique ou partielle…
2.4 Synthèse
Aucune étude ne semble correspondre exactement au sujet qui nous intéresse. Pour ce qui est des systèmes basés sur un gant sensoriel, ils sont encombrants et invasifs. Ils ne se concentrent également que sur un seul articulateur manuel sans prendre en compte les expressions du visage ni le regard, ou les mouvements du corps. Les applications citées plus haut ont été entrainées sur une trentaine de signes seulement, ne prenant donc en compte que l’aspect lexical. Ils seraient mieux adaptés pour de la reconnaissance d’épellation, mais ne peuvent être identifiés comme des systèmes de traduction puisque les LS ne se résument pas à de l’épellation. Bien que les technologies d’avatar s’améliorent, on ne peut pas réellement parler d’outils de traduction dans ces cas, puisqu’à nouveau ils ne se basent que sur du lexique, avec une grammaire rigide et aucun retour sur l’iconicité.
Pour ce qui est points clés identifiés pour le fonctionnement des logiciels de TAO déjà existants, chacun semble soulever un problème quant à leur éventuelle adaptation à la langue des signes :
-
Dans un premier temps, elles ne disposent pas de forme écrite éditable.
-
L’usage d’une mémoire de traduction semble compromis en l’état : que stocker avec les LS ? Les vidéos ne sont pas requêtables, ni éditables, et rapidement encombrantes à stocker.
-
Enfin concernant le principe de linéarité, est-il seulement valable également pour la traduction des LS ?
Au vu de toutes ces informations, les objectifs de départ de notre recherche étaient les suivants :
-
Identifier les étapes constitutives de la traduction en LSF, si elles sont systématiques
-
Identifier les besoins des professionnels, ainsi que les obstacles qu’ils rencontrent dans leur travail
-
Déterminer quelles assistances informatiques pourraient répondre à ces besoins
-
Dresser une première spécification d’interface et d’outils pour le logiciel destiné aux langues signées.
Le paragraphe suivant décrit notre étude préliminaire destinée à rassembler des informations subjectives et objectives quant aux pratiques professionnelles des traducteurs en LS.
3. Analyse des pratiques professionnelles
Pour déterminer les étapes de la traduction français-LSF, nous avons mené deux études avec l’aide de traducteurs professionnels.
Nous avons d’une part organisé un brainstorming, pour les inviter à s’exprimer sur leurs pratiques professionnelles quotidiennes ainsi que sur les différents obstacles qu’ils pouvaient rencontrer. Cette session était suivie d’une discussion libre, pour revenir sur les idées formulées plus tôt et réfléchir sur d’éventuelles solutions à leurs besoins. La rareté des ressources en LSF ainsi que le besoin d’un outil qui permette de capitaliser sur le travail passé furent les deux points les plus souvent mentionnés. Notons que les professionnels peinent à formuler des besoins précis, n’ayant jamais songé ou n’ayant pas connaissance des possibilités offertes par l’informatique. Après une brève introduction aux pratiques existantes dans la traduction d’autres langues, ils ont pu dresser une liste de besoins et de problèmes rencontrés quotidiennement dans leur exercice professionnel.
D’autre part, afin de récolter des données plus objectives, nous avons également filmé des traducteurs à l’œuvre. Par binômes, nous leur avons soumis plusieurs textes à traduire, en les laissant libres de procéder selon leurs méthodes. Cela nous permet ainsi de lister les tâches qui composent chaque exercice de traduction, mais également de prendre connaissance des obstacles qu’ils rencontrent puisqu’ils sont en mesure de le verbaliser et d’en discuter ensemble. L’analyse de ces vidéos montre que les traducteurs pourraient bénéficier d’outils d’aide au traitement du texte (reconnaissance d’entités nommées, automatisation de recherches encyclopédiques...), mais également de plus de ressources en langue des signes. Le résultat de cette étude ayant impliqué un binôme de traducteurs expérimentés et un autre débutant est synthétisé dans le tableau suivant (fig.1).
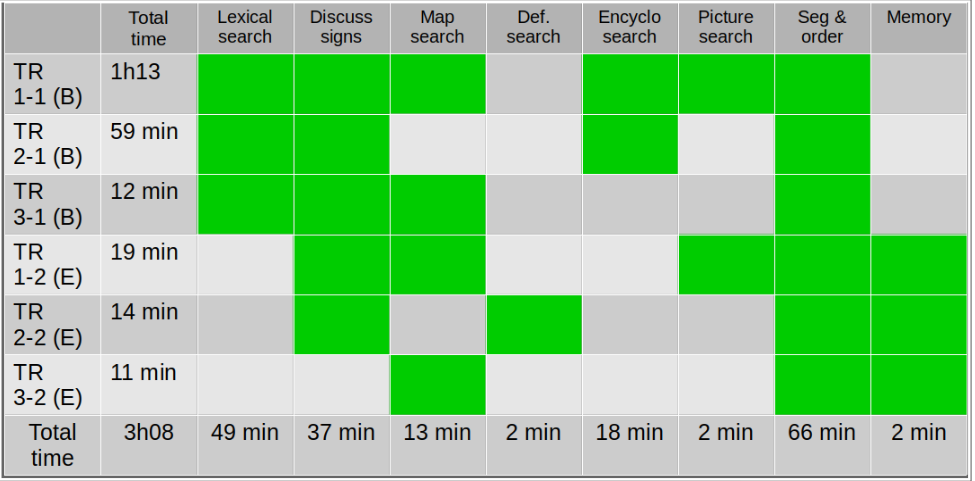
Figure 1 - Tâches effectuées par les binômes de traducteurs débutants ou expérimentés
A chaque ligne correspond une traduction étudiée. Les trois premières sont produites par le binôme «B» (débutant). Les trois autres sont les productions du groupe E (expérimenté). Chacune des colonnes qui suit correspond à une tâche identifiée lors de l’analyse des vidéos des traducteurs à l’œuvre:
-
Recherche lexicale (lexical search) : sollicitation de diverses ressources pour trouver le signe le plus adéquat à la traduction d’un concept, noms propres inclus
-
Discussions (discuss signs) : débats ou discussions au sein du binôme, pour nuancer le sens afin de choisir le signe qui correspond le mieux au contexte
-
Recherche de cartes (map search) : lorsque le texte source concerne les relations topographiques et géographiques entre plusieurs lieux, recherche de cartes.
-
Recherche de définitions (def. search) : recherche de définition dans la langue source, ici en français.
-
Recherche encyclopédique (encyclo search) : recherche de contexte ou de données encyclopédiques, lorsque le texte source fait référence à des évènements passés dont la connaissance est nécessaire pour mener à bien la traduction.
-
Recherche d’images (picture search) : recherche d’images, pour décrire ou suggérer un signe pour des concepts qui n’en ont pas, ou pour mieux comprendre l’élément à traduire.
-
Segmentation et ordre (seg. & order) : cette tâche consiste à découper le texte source en plus petites unités, et à adapter leur ordre pour qu’il soit conforme à la LSF. Un traducteur suggère un ordre, signe à son binôme, puis ils discutent pour modifications éventuelles.
-
Mémorisation (memory) : le traducteur qui sera filmé s’entraîne pour lui-même à mémoriser sa production, sans intervention de son binôme.
On remarque que la tâche de segmentation et d’organisation du discours est non seulement la seule qui soit systématique, mais également celle qui consomme le plus de temps (un tiers de la durée totale de traduction). Du reste, nous avons pu observer dans tous les résultats produits par les traducteurs que les informations sont livrées dans un ordre différent de l’ordre source. De fait, en LSF, le principe de linéarité n’est pas admis d’office, ni ne semble s’appliquer.
Ces données objectives nous ont permis de brosser une description plus précise du processus de traduction français/LS. En complément des données subjectives déjà récoltées, elles nous permettent de couvrir un maximum des aspects du métier via la combinaison des deux points de vue. En effet, les personnes interrogées tendent à mentionner des activités que nous n’observons pas sur le terrain, et à l’inverse, à omettre des tâches qui semblent pourtant importantes. Dans le cas de ces deux études, les résultats se corroborent mutuellement.
En compilant les résultats de ces deux études, nous avons pu préciser des spécifications quant à l’élaboration d’un logiciel de TAO pour les LS, et proposer des solutions à chacun des problèmes identifiés plus tôt. Il apparait nécessaire de sortir de l’objectif seul d’adapter un logiciel de TAO existant pour les LS, au profit de la création d’un outil dédié. L’outil devra être en mesure de proposer une aide à la segmentation et à la gestion de l’ordre sans pour autant l’imposer au traducteur. Il devra de même proposer un accès facilité aux ressources en LS, ainsi qu’à des outils de recherche encyclopédique. Enfin, le logiciel devra supporter des formats autres que le texte (vidéos, images et cartes, schémas).
La section suivante explore une réponse possible quant à l’usage d’une mémoire de traduction destinée aux LS.
4. Mémoire de traduction pour les LS
Nous avons jusque là déterminé trois problèmes majeurs quant à la création d’un outil de TAO pour assister les LS, à savoir : l’absence de forme écrite éditable, l’incompatibilité du principe de linéarité, et le fonctionnement d’une mémoire de traduction adaptée aux modalités de la langue. Cette section s’intéresse à la résolution de ce problème. Comme aucune autre étude ne s’est encore intéressée à la question, l’état de l’art ne fournit que peu d’éléments sur lesquels se baser. Pour adapter le concept de la mémoire de traduction à la LSF, nous travaillons sur un concordancier français-LSF. Un concordancier, quelles que soient ses langues de travail, est un outil logiciel qui permet de chercher et de lister toutes les occurrences d’une requête dans un corpus ou une base de données. Les concordanciers bilingues sont tout particulièrement utiles en traduction. La requête est formulée dans la langue source, et les résultats en langue cible sont fournis en contexte. Pour élaborer notre concordancier, nous avons dans un premier temps dû élaborer la base de données des alignements qu’il parcourra. Dans notre cas, la requête se fait en français écrit, et les résultats figurent sous forme d’extraits vidéo de LSF. Un alignement correspond à un segment du texte source, lequel a été associé à sa traduction sous format vidéo. Les paragraphes suivants détaillent la création comme l’implémentation de l’outil, ainsi que des exemples d’usage.
4.1 Méthodologie
Pour ce faire, nous avons utilisé un corpus parallèle français-LSF (40-brèves), qui se compose de 40 brèves journalistiques chacune traduite par 3 traducteurs professionnels, pour un total de 120 vidéos d’environ 30 secondes chacune. Comme les brèves et leurs traductions sont assez courtes, nous pouvons aligner la totalité du texte avec la totalité de la vidéo pour créer 3 alignements par brèves. L’objectif est ensuite de créer des alignements plus courts. Les textes ont donc été segmentés en plus petites unités : des expressions idiomatiques, phénomènes grammaticaux, mots ou expressions sans signe standard, figure de style ou de construction... Seuls les segments de texte convenablement “alignables” sont conservés. Par exemple, on ne peut pas aligner un adverbe dans le texte avec juste l’expression faciale du signeur, puisque la vidéo contiendrait de fait d’autres informations, comme les paramètres manuels, qui eux ne seraient pas présents dans le texte. Les alignements doivent être faits manuellement puisqu’il n’existe actuellement aucun moyen de le faire de façon automatique (qui nécessiterait une reconnaissance pointue des signes). Avec trois signeurs différents pour chaque brève, les segments sont de taille variée. Pour contourner les contraintes liées à l’usage de la vidéo, les segments vidéos ne sont pas découpés et stockés tels quels. En effet, les vidéos sont difficilement éditables, requêtables, et consomment beaucoup d’espace de stockage. Les segments de vidéos sont donc identifiés par le biais de balises temporelles. A chaque segment correspond donc un temps de départ, une durée, et l’identifiant de la vidéo dans laquelle ces balises sont valables. Les segments de texte sont identifiés d’une manière similaire, par l’indice du premier caractère du segment dans le texte, sa longueur, et l’identifiant du texte. Pour créer un alignement, il faut ensuite rassembler toutes ces informations en une seule entrée pour les stocker dans la base de données, sous la forme suivante :
<TxtId, start pos., length, VidID, start time, duration>
que l’on peut expliquer ainsi :
-
TxtId est le code d’identification unique du texte, qui permet de le retrouver dans l’emplacement de stockage dédié.
-
start pos. est l’indice du premier caractère du segment, dans le texte
-
length est la longueur du segment texte, en nombre de caractères
-
vidID est le code d’identification unique de la vidéo, qui permet de la retrouver dans l’emplacement de stockage dédié.
-
start time est la balise temporelle correspondant au début du segment dans la vidéo
-
duration est la durée (en secondes) du segment vidéo
En parallèle du fichier d’alignements lui-même, des fichiers de métadonnées conservent des informations complémentaires concernant les textes et les vidéos qui constituent le corpus. Le but est de garder une trace accessible d’informations dont la mention pourrait être pertinente dans l’interface finale du concordancier. Les fichiers de métadonnées (un pour les textes, un pour les vidéos) sont donc destinés à lister des informations telles que les auteurs, les informateurs, les sources, les titres originaux ou encore les thèmes abordés.
4.2 Implémentation
La base de données actuelle contient environ 450 alignements créés manuellement, dont 120 alignements totaux (tout le texte aligné avec toute la vidéo). C’est une base modeste, mais que nous nourrissons régulièrement. Pour ce faire, en sus d’une fonction de recherche pour explorer son contenu, le concordancier compte également une fonction d’alignement.
4.2.1 Fonction de recherche
Le concordancier est librement accessible en ligne1. La figure 2 montre la disposition de la page de résultats d’une requête. Le segment aligné qui contient la requête est surligné en jaune dans le texte, qui apparait d’ailleurs en entier pour fournir du contexte à l’utilisateur. La requête exacte est, quant à elle, mise en gras. Le titre situé au dessus du texte fournit les informations le concernant : l’identifiant du texte ici, ainsi que start pos. et length du segment matché. Cliquer sur l’identifiant du texte ouvre un onglet supplémentaire qui contient l’intégralité du texte (pour le cas où celui-ci serait trop long à afficher entièrement sur la page de résultats du concordancier). De façon similaire, le segment vidéo est surligné en jaune dans la barre de défilement de la vidéo. Le titre affiche les mêmes informations que pour le texte, à savoir l’identifiant de la vidéo (qui permet d’ouvrir la vidéo dans un nouvel onglet), start time et duration pour le segment affiché. L’utilisateur peut choisir d’afficher plus ou moins de contexte à droite et à gauche du segment via les boutons dédiés (A et B sur la figure 2). Le bouton “voir segment” permet de recentrer le lecteur sur ce dernier. La vidéo est jouée en boucle.
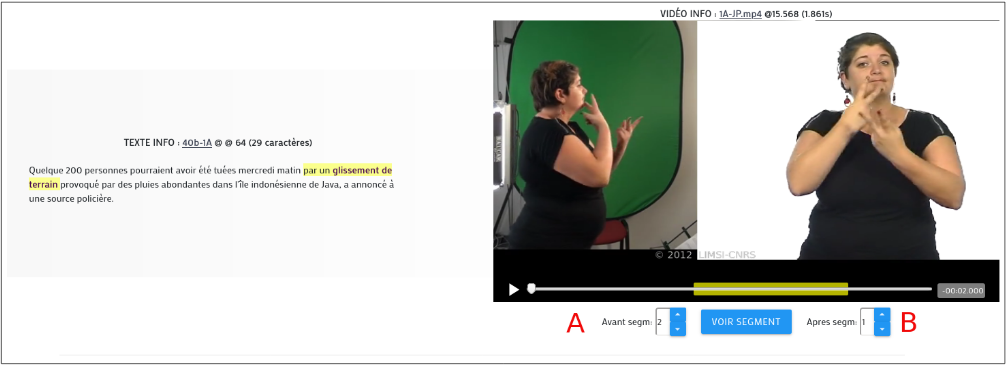
Figure 2 - Disposition de la page de résultats d’une requête
Bien que les requêtes soient le plus souvent des correspondances exactes, la fonction de recherche inclut la possibilité d’une requête partielle complétée par un affixe :
-
Le suffixe “#” permet de faire correspondre toutes les occurrences d’un radical quelle que soit sa terminaison, avec ou sans limite de longueur. Pour déterminer cette éventuelle limite, il suffit d’ajouter la longueur maximum désirée à la suite. Par exemple, la requête « Europ# » renverrait comme résultats : Europe, européen, européens, européenne, européennes...
-
Le suffixe “##” permet de rechercher une séquence de mots contenant une rupture. Par exemple, la requête « quelques ## personnes » pourrait renvoyer comme résultats quelques personnes, quelques 200 personnes, quelques deux cents personnes, quelques milliers de personnes... On peut également poser une condition sur le nombre de mots que contient la rupture, en ajoutant également le nombre désiré à la suite du suffixe.
Fonction d’alignement
Comme annoncé précédemment, le concordancier repose sur une base de données d’alignements réalisés manuellement à l’aide d’un seul corpus parallèle. L’objectif, pour rendre l’outil plus performant, est bien entendu d’agrandir cette base de données, en y ajoutant des alignements supplémentaires mais également en variant le contenu aligné puisque pour l’heure, elle ne contient que des brèves journalistiques. Nous avons d’ailleurs invité nos collaborateurs à participer à une collecte de contenu parallèle. Dans l’optique d’enrichir le concordancier, il faudra bien entendu générer des alignements à partir du nouveau contenu, ce qui était jusqu’à lors une tâche fastidieuse et complexe du fait du manque d’outil adapté (utilisation de plusieurs logiciels en parallèle, traitement manuel des données, nécessité de mettre à jour l’outil en ligne à chaque ajout dans la base de données). Pour nous faciliter la tâche, et peut-être encourager nos collaborateurs à y prendre part, nous avons également développé une fonction d’alignement, disponible en ligne et directement intégrée au concordancier. Une page unique permet de générer un alignement et de l’ajouter à la base de données en quelques clics. Dans un premier temps, l’utilisateur doit sélectionner le bicontenu sur lequel il désire travailler. Il choisit donc un texte parmi la liste des fichiers disponibles, puis la vidéo qu’il souhaite aligner, sachant que les vidéos proposées sont déjà identifiées comme étant des traductions du texte sélectionné. A noter : il est également possible de sélectionner d’abord la vidéo puis le texte. Une fois le bicontenu validé, la fonction d’alignement est affichée comme suit (fig. 3) :
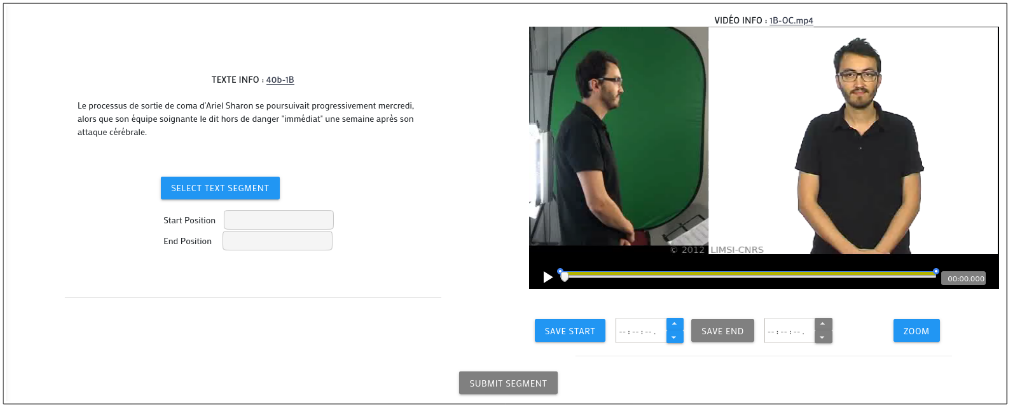
Figure 3 - Affichage de la fonction d’alignement du concordancier
La création d’un alignement comporte deux étapes :
-
Sélectionner dans le texte le segment que l’on désire aligner, en surlignant avec la souris. Les indices des premier et dernier caractères de la chaine apparaissent dans les fenêtres dédiées à titre indicatif (non éditables manuellement). On clique ensuite sur “select text segment” pour valider le choix.
-
Dans la vidéo, on repère la traduction du segment précédemment sélectionne, et on identifie son début et sa fin avec les boutons “save start” et “save end”. Ces deux boutons permettent de positionner des balises dans la barre de défilement de la vidéo, et d’extraire le temps correspondant, affiché dans la fenêtre adjacente. Le bouton “Zoom” permet, si la vidéo est trop longue, de zoomer sur la barre de défilement pour faciliter le positionnement des balises.
Une fois ces deux étapes réalisées, l’utilisateur peut enregistrer son alignement en cliquant sur “Submit segment”. Ce dernier est alors ajouté dans la base de données. A noter que chaque utilisateur dispose de son propre fichier d’alignements, ce qui nous permet de garder plus facilement la main sur ce qui est ajouté dans le concordancier, pour modification ou suppression en cas d’erreur. A terme, il sera possible, lors du lancement d’une requête dans le concordancier, de filtrer par contributeurs les fichiers dans lequel la recherche est effectuée. Cette fonction constitue un gain de temps considérable dans la création des alignements, faute d’automatisation possible.
4.3. Exemples d’utilisations
Comme l’ont mentionné les professionnels interrogés lors du brainstorming, les ressources en langue des signes sont rares. De même, les ressources existantes sont pour la plupart mal documentées voire difficiles d’accès. Au-delà de l’utilité du concordancier dans la traduction, c’est également une façon unique d’explorer la langue. Il pourrait servir non seulement à illustrer l’enseignement de la LSF, mais également être un outil pédagogique dans la formation des interprètes et des traducteurs professionnels. Il permet effectivement de trouver et d’afficher de façon lisible non seulement du lexique et des phénomènes grammaticaux en contexte, mais également de mettre en lumière certains choix ou méthodes de traduction.
Lors d’un atelier de présentation de l’outil par nos soins, nous avons proposé aux professionnels de la traduction présents de consulter plusieurs textes, et d’isoler les expressions qu’ils seraient le plus à même de rechercher dans notre concordancier. Voici trois des exemples les plus souvent mentionnés.
4.3.1 Pas de signe standard, mais forme commune
Certaines expressions figées du français n’ont pas d’équivalent direct en LSF. C’est le cas de l’expression “fin de non-recevoir”. Le fait qu’il n’y ait pas de signe standard pour une expression ne signifie pas qu’elle est intraduisible pour autant. Quand on recherche “fin de non-recevoir” dans notre concordancier, on obtient trois résultats. Notons que les trois traducteurs ont toujours travaillé seuls sur chacune de leurs traductions. Ils utilisent pourtant ici (fig. 4) tous les trois une structure similaire, à savoir le signe “refuser, rejeter”. Leurs expressions du visage sont également identiques, tout comme la structuration spatiale de leur traduction. Le texte source dans son intégralité est d’ailleurs traduit de façon très similaire, ce qui souligne le peu d’impact du contexte sur les choix de traduction à l’œuvre dans ce cas précis.

Figure 4 - Trois traductions de l’expression « fin de non-recevoir »
Le fait que la forme soit trois fois identique peut inspirer confiance malgré l’absence de signe standard. Ce genre de résultats peut conforter le traducteur dans ses choix de traduction, ou l’encourager à faire usage de la même structure dans sa propre traduction.
4.3.2 Pas de signe standard, et pas de forme commune.
Il s’agit cette fois de l’expression “mis à mal”, qui ne présente pas d’équivalent hors contexte en LSF. On trouve trois exemple de traduction dans notre base de données, et ces trois occurrences sont différentes les unes des autres (fig.5). La phrase qui contient le segment est la suivante: “Les espoirs de paix au Sri Lanka sont de nouveau mis à mal après le lancement mercredi d'une grande offensive militaire contre la rébellion tamoule dans le nord de l'île”.

Figure 5 - Trois traductions de l’expression « mis à mal »
Le signeur de gauche utilise le signe “casser”, et celui de droite opte pour “difficile”. Le signeur du milieu utilise une structure iconique basé sur le signe “espoir”, qui ici s’écroule. Dans cet exemple, la traduction est notablement plus influencée par le contexte que précédemment. Trois traductions différentes sont proposées pour une même expression dans un même contexte. Cet exemple met en lumière tout l’intérêt du concordancier, à savoir la variété des occurrences que l’on peut obtenir pour un même contexte. Les professionnels peuvent capitaliser sur le travail passé, et les apprenants de la langue peuvent mieux appréhender la finesse et la richesse de la langue.
4.3.3 Relation cause/effet
Le concordancier est également une façon intéressante d’observer certains phénomènes grammaticaux. La relation de cause à effet peut être traduite de nombreuses façons en LSF, en fonction du contexte et des choix du traducteur. Elle peut se traduire par l’utilisation du signe « conséquence », « à la suite », comme c’est le cas pour le signeur de droite sur la figure ci-dessous (fig. 6). Les deux autres signeurs présentés ont fait le choix d’utiliser des structures iconiques qui décrivent l’évènement, à savoir : un séisme sous-marin provoque un tsunami. Dans ces cas, la relation de cause à effet réside dans la succession des évènements, aussi bien que dans les expressions des visages des traducteurs et dans la dynamique du discours. On remarque un temps de transition spécifique entre les deux évènements mentionnés.

Figure 6 – Trois traductions de la phrase « un séisme sous-marin provoque un tsunami »
Sur la figure suivante (fig.7), la phrase à traduire était : « un glissement de terrain causé par des pluies abondantes ». Les deux traducteurs décrivent la pluie, le sol gorgé d’eau, puis le glissement de terrain en lui-même. Les captures d’écran sont prises juste avant le signe du glissement de terrain, et l’on peut voir qu’ici encore la relation de cause à effet réside dans la succession des évènements décrits comme dans les expressions du visage, mais également dans le temps de transition très bref entre les deux, avec les sourcils haussés et le menton relevé pour attirer l’attention du spectateur.

Figure 7 – Deux traductions de la phrase « un glissement de terrain causé par des pluies abondantes »
5. Conclusion
Dans cet article, nous nous sommes penchés sur la question de la traduction en LS, et de la manière d’outiller la LSF au même titre que les autres langues. Nous nous sommes d’abord penchés sur la traduction d’un point de vue théorique, puis sur les outils déjà existants. Constatant l’absence de logiciels de TAO qui puissent prendre en charge les LS, ou de tout autre outil qui assiste la traduction des LS tout en laissant place au traducteur humain en tant qu’expert, nous avons étudié les logiciels existants pour les autres langues et en avons déterminé les trois points clés. Pour connaître le métier et identifier en détail les besoins des professionnels de la traduction, nous avons mené deux expériences qui nous ont permis de dresser une première liste de spécifications pour un tel logiciel, ainsi qu’une liste de tâches constitutives du processus de traduction. Ces trois points clés ont eux-mêmes fait émerger trois problèmes majeurs quant à la question de l’outillage des LS, qui transparaissent également au travers des résultats de nos études : pas de forme écrite éditable, non-application du principe de linéarité, et nécessité de repenser le fonctionnement d’une mémoire de traduction. Comme solution apportée à ce dernier point, nous avons élaboré un concordancier français-LSF pour permettre le stockage durable de traductions précédentes ainsi qu’une exploration de la langue en contexte.
La différence majeure entre TAO texte à texte et TAO des LS repose sur la nécessité de gérer d’autres formats que l’écrit seul. Là où les logiciels actuels reposent sur l’automatisation de tâches (segmentation, alimentation de la mémoire de traduction, traduction partiellement automatique grâce à cette dernière), la TAO des LS s’orienterait plutôt vers la nécessité d’un environnement de travail intégré à même de gérer les besoins propres à la langue : schémas, vidéos, recherche encyclopédique, réorganisation de l’ordre du discours. C’est l’objectif de notre recherche actuelle, qui vise à répondre aux deux problèmes restants parmi les trois identifiés plus haut. L’environnement de traduction en question reposerait d’une part sur la génération de blocs pouvant accueillir n’importe quel type de contenu (texte, vidéo, schéma, image) toute en restant mobiles pour faciliter l’organisation du discours, et d’autre part sur plusieurs modules annexes destinés aux différents types de recherches (lexicale, encyclopédique, invocation du concordancier).
L’évaluation des outils décrits reposera sur plusieurs métriques simples. La vitesse de traduction d’une part : le traducteur est-il plus rapide lorsqu’il utilise le logiciel ? Le confort de travail, ensuite : subjectivement, le traducteur se sent-il plus à l’aise lorsqu’il est assisté par le logiciel ? Cela peut revenir à des questions d’ergonomie comme à des questions de confiance en soi du fait de pouvoir mobiliser des outils dédiés. Enfin, d’un point de vue de la qualité : les traductions produites avec l’aide du logiciel sont-elles jugées comme étant d’une qualité moindre, égale, ou supérieure à celle de traductions dites « non-assistées » ?
Cette étude n’aurait pu avoir lieu sans l’aimable participation des traducteurs professionnels volontaires, que nous tenons à remercier. Nous espérons que ces travaux, bien que pionniers, puissent aboutir à outiller les traducteurs en langue des signes au même titre que leurs collègues du texte à texte.